

Google BigQuery được phát hành phổ biến vào năm 2011 và là kho dữ liệu (Data Warehouse) doanh nghiệp của Google Cloud được thiết kế phục vụ cho sự linh hoạt trong kinh doanh. Kiến trúc không máy chủ cho phép nó vận hành ở quy mô mở rộng và tốc độ phân tích SQL cực kỳ nhanh trên các tập dữ liệu lớn. Kể từ khi phát hành, nhiều tính năng và cải tiến đã được thực hiện để cải thiện hiệu suất, bảo mật, độ tin cậy và giúp người dùng khám phá insights dễ dàng hơn.
Data Warehouse trợ giúp các quyết định kinh doanh như thế nào?
Data warehouse tổng hợp dữ liệu từ nhiều nguồn khác nhau và thực hiện phân tích trên dữ liệu tổng hợp để gia tăng giá trị cho hoạt động kinh doanh bằng cách cung cấp thông tin hữu ích (insights). Data warehouse là nơi lưu giữ dữ liệu kinh doanh quan trọng nhất của doanh nghiệp trong hai thập kỷ qua. Khi các doanh nghiệp ngày càng trở nên theo định hướng dữ liệu, data warehouse ngày càng đóng vai trò quan trọng trong hành trình chuyển đổi số của họ. Theo Gartner, data warehouse thường là nền tảng của chiến lược phân tích doanh nghiệp. Các trường hợp sử dụng data warehouse đã vượt ra ngoài báo cáo hoạt động truyền thống. Ngày nay, các doanh nghiệp cần:
- Có cái nhìn 360⁰ về hoạt động kinh doanh của họ: Dữ liệu có giá trị. Khi chi phí lưu trữ và xử lý dữ liệu giảm, các doanh nghiệp muốn xử lý, lưu trữ và phân tích tất cả các tập dữ liệu có liên quan, cả nội bộ và bên ngoài tổ chức của họ.
- Nhận diện được tình huống và phản ứng nhanh với các sự kiện kinh doanh trong thời gian thực: Doanh nghiệp cần có được những hiểu biết sâu sắc từ các sự kiện thời gian thực chứ không phải đợi hàng ngày hoặc hàng tuần để phân tích dữ liệu. Data warehouse cần phải phản ánh tình trạng kinh doanh hiện tại tại mọi thời điểm
- Giảm thời gian tìm thông tin hữu ích (insights): Doanh nghiệp cần thiết lập và vận hành nhanh chóng mà không cần chờ đợi hàng ngày hoặc hàng tháng. Hoặc phải chờ đợi phần cứng hoặc phần mềm được cài đặt hoặc cấu hình.
- Tạo sẵn các báo cáo hữu ích cho người dùng doanh nghiệp để cho phép ra quyết định theo hướng dữ liệu trong toàn doanh nghiệp: Để áp dụng văn hóa dựa trên dữ liệu, các doanh nghiệp cần dân chủ hóa quyền truy cập vào dữ liệu.
- Bảo mật dữ liệu của họ và quản lý việc sử dụng dữ liệu: Dữ liệu cần được bảo mật và có thể truy cập được đối với người dùng bên trong và bên ngoài doanh nghiệp.
Khi các doanh nghiệp muốn mở rộng việc sử dụng các kho dữ liệu truyền thống với khối lượng dữ liệu ngày càng tăng, họ phải đối mặt với những thách thức to lớn khi chi phí của họ tiếp tục vượt ngoài tầm kiểm soát do TCO (Total Cost of Ownership – Tổng chi phí sở hữu) cao hơn. Kho dữ liệu truyền thống không được thiết kế để xử lý sự phát triển bùng nổ về dữ liệu và chắc chắn không được xây dựng cho các kiểu xử lý dữ liệu mới nổi.
BigQuery—Data Warehouse trên nền tảng Cloud
Google BigQuery được thiết kế như một kho dữ liệu thuần đám mây (cloud-native). Nó được xây dựng để giải quyết nhu cầu của các tổ chức theo định hướng dữ liệu trong xu hướng thế giới đám mây đầu tiên.
BigQuery là kho dữ liệu đám mây không máy chủ, có khả năng mở rộng cao và hiệu quả về chi phí trên GCP. Nó cho phép thực hiện các truy vấn siêu nhanh ở quy mô petabyte bằng cách sử dụng sức mạnh xử lý của cơ sở hạ tầng của Google. Vì không có cơ sở hạ tầng để khách hàng quản lý, họ có thể tập trung vào việc khám phá báo cáo hữu ích có ý nghĩa bằng cách sử dụng SQL quen thuộc mà không cần quản trị viên cơ sở dữ liệu. Nó cũng tiết kiệm vì họ chỉ trả tiền cho quá trình xử lý và lưu trữ mà họ sử dụng.
BigQuery sẽ phù hợp ở đâu trong vòng đời dữ liệu?
BigQuery là một phần của nền tảng phân tích dữ liệu toàn diện của Google Cloud, bao gồm toàn bộ chuỗi giá trị phân tích bao gồm nhập, xử lý và lưu trữ dữ liệu, sau đó là phân tích nâng cao và kết hợp. BigQuery được tích hợp sâu với các dịch vụ phân tích và xử lý dữ liệu của GCP, cho phép khách hàng sẵn sàng thiết lập data warehouse thuần đám mây cho doanh nghiệp.
Ở mỗi giai đoạn của vòng đời dữ liệu, GCP cung cấp nhiều dịch vụ để quản lý dữ liệu. Điều này có nghĩa là khách hàng có thể lựa chọn một bộ các dịch vụ phù hợp với dữ liệu và quy trình làm việc của mình.

Nhập dữ liệu vào BigQuery
BigQuery hỗ trợ một số cách để nhập dữ liệu vào khu vực quản lý lưu trữ của nó. Phương pháp nhập cụ thể phụ thuộc vào nguồn của dữ liệu. Ví dụ: một số nguồn dữ liệu trong GCP, như Cloud Logging và Google Analytics, hỗ trợ xuất trực tiếp sang BigQuery.
Dịch vụ truyền dữ liệu BigQuery cho phép truyền dữ liệu sang BigQuery từ các ứng dụng Google SaaS (Google Ads, Cloud Storage), Amazon S3 và các kho dữ liệu khác (Teradata, Redshift).
Dữ liệu truyền trực tuyến, chẳng hạn như nhật ký hoặc dữ liệu thiết bị IoT, có thể được ghi vào BigQuery bằng cách sử dụng đường ống Cloud Dataflow, Cloud Dataproc jobs hoặc trực tiếp sử dụng luồng nhập API của BigQuery.
Kiến trúc BigQuery
Kiến trúc không máy chủ của BigQuery phân tách lưu trữ và tính toán, đồng thời cho phép chúng mở rộng quy mô độc lập theo nhu cầu. Cấu trúc này cung cấp cả tính linh hoạt và kiểm soát chi phí cho khách hàng vì họ không cần phải duy trì các tài nguyên tính toán đắt tiền và chạy chúng mọi lúc. Điều này rất khác với các giải pháp kho dữ liệu đám mây dựa trên nút (node-base) truyền thống hoặc các hệ thống xử lý song song (MPP) hàng loạt tại chỗ (on-premise ). Cách tiếp cận này cũng cho phép khách hàng ở mọi quy mô đưa dữ liệu của họ vào kho dữ liệu và bắt đầu phân tích dữ liệu của họ bằng Standard SQL mà không cần lo lắng về các hoạt động cơ sở dữ liệu và kỹ thuật hệ thống.
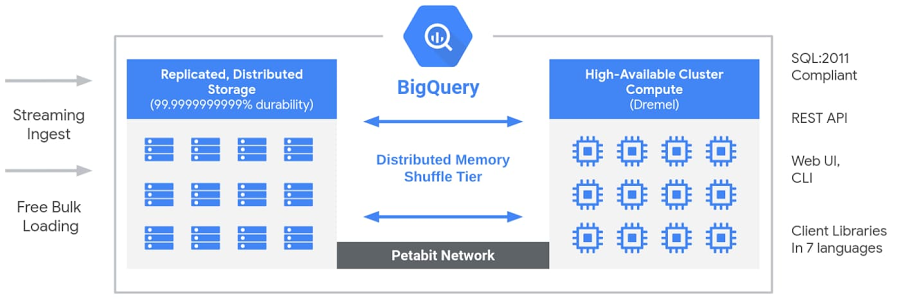
Bên cạnh đó, BigQuery sử dụng một loạt các dịch vụ dành cho nhiều người thuê được thúc đẩy bởi các công nghệ cơ sở hạ tầng cấp thấp của Google như Dremel, Colossus, Jupiter và Borg.
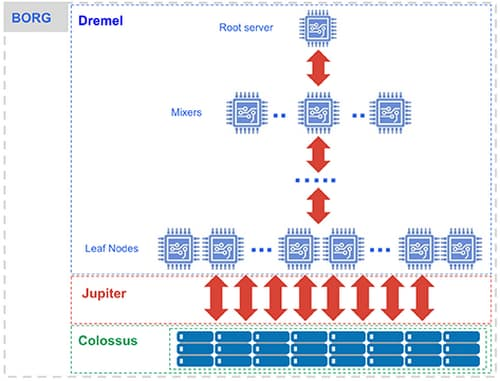
Hệ thống xử lý dùng Dremel, một cụm hệ thống đa khách hàng lớn thực thi các truy vấn SQL.
- Dremel biến các truy vấn SQL thành cây thực thi. Các lá của cây được gọi là chỗ và thực hiện nhiệm vụ đọc dữ liệu từ kho lưu trữ và bất kỳ tính toán cần thiết nào. Các nhánh của cây là ‘máy trộn’, thực hiện việc kết hợp.
- Dremel tự động sắp xếp các chỗ cho các truy vấn trên cơ sở khi cần thiết, duy trì sự công bằng cho các truy vấn đồng thời từ nhiều người dùng. Một người dùng đơn có thể nhận được hàng nghìn vị trí để chạy các truy vấn của họ.
Hệ thống lưu trữ dùng Colossus, là hệ thống lưu trữ toàn cầu của Google.
- BigQuery tận dụng định dạng lưu trữ dạng cột và thuật toán nén để lưu trữ dữ liệu trong Colossus, được tối ưu hóa để đọc một lượng lớn dữ liệu có cấu trúc.
- Colossus cũng quản lý nhân bản, phục hồi (khi đĩa gặp sự cố) và quản lý phân tán (vì vậy không có điểm nào bị lỗi). Colossus cho phép người dùng BigQuery mở rộng quy mô lên hàng tá petabyte dữ liệu được lưu trữ liền mạch mà không phải trả khoản tiền vượt khi bổ sung thêm các tài nguyên tính toán tốn phí như trong các kho dữ liệu truyền thống.
Tính toán và lưu trữ trao đổi với nhau thông qua kiến trúc mạng Jupiter lên đến hàng petabit.
- Trong khi giữa lưu trữ và tính toán là ‘sự đảo chiều’, thì nó đã tận dụng mạng Google Jupiter để di chuyển dữ liệu cực kỳ nhanh chóng từ nơi này sang nơi khác.
BigQuery được tổ chức thông qua Borg, nó tiền thân của Google Kubernetes.
- Các bộ trộn và các chỗ đều do Borg điều hành, với các tài nguyên phần cứng được cấp phát.
Google rất chú trọng vào việc liên tục cải tiến để những công nghệ này tốt hơn. Người dùng BigQuery nhận được lợi ích của những cải tiến liên tục về hiệu suất, độ bền, hiệu quả và khả năng mở rộng mà không cần thời gian ngừng hoạt động và nâng cấp như các công nghệ truyền thống. Nếu bạn muốn biết thêm chi tiết về kiến trúc BigQuery, hãy xem bài viết này để có bản đồ cấu trúc liên kết đầy đủ hơn về BigQuery.
Bắt đầu với BigQuery như thế nào?
Bạn có thể bắt đầu sử dụng BigQuery đơn giản bằng cách tải dữ liệu và chạy các lệnh SQL. Không cần phải xây dựng, triển khai hoặc các cụm cung cấp; không cần kích thước máy ảo, lưu trữ hoặc tài nguyên phần cứng; không cần thiết lập đĩa, xác định sao chép, định cấu hình nén và mã hóa hoặc bất kỳ công việc thiết lập hoặc cấu hình nào khác cần thiết để xây dựng kho dữ liệu truyền thống ..
Để giúp bạn bắt đầu với BigQuery, BigQuery sandbox cung cấp cho bạn quyền truy cập miễn phí vào khả năng của BigQuery, cung cấp 10GB lưu trữ miễn phí và 1TB dữ liệu truy vấn được phân tích mỗi tháng. Xem tập BigQuery Spotlight này để biết cách thiết lập BigQuery sandbox, cho phép bạn chạy các truy vấn mà không cần thẻ tín dụng.
Sử dụng BigQuery sandbox
Bạn có thể truy cập BigQuery theo nhiều cách:
- Sử dụng bảng điều khiển GCP
- Sử dụng công cụ dòng lệnh bq
- Thực hiện lệnh gọi tới API BigQuery REST
- Sử dụng nhiều thư viện khách như Java, .NET hoặc Python
- Hãy thử ngay bây giờ. Điều hướng đến giao diện người dùng web BigQuery trên Google Cloud Console, sao chép và dán truy vấn sau, sau đó nhấn nút “Chạy”.
Language: SQL
1<code>SELECT2 EXTRACT(YEAR FROM creation_date) AS year,3 EXTRACT(MONTH FROM creation_date) AS month,4 COUNT(creation_date) AS number_posts5FROM6 `bigquery-public-data.stackoverflow.stackoverflow_posts`7WHERE8 answer_count > 09GROUP BY year, month10ORDER BY year ASC, month ASC;</code>
Truy vấn xử lý ~ 30GB bài đăng trên StackOverflow có sẵn từ năm 2008 đến năm 2016 trong tập dữ liệu BigQuery công khai, để tìm số lượng bài đăng có ít nhất một câu trả lời được đăng, được nhóm theo năm và tháng.
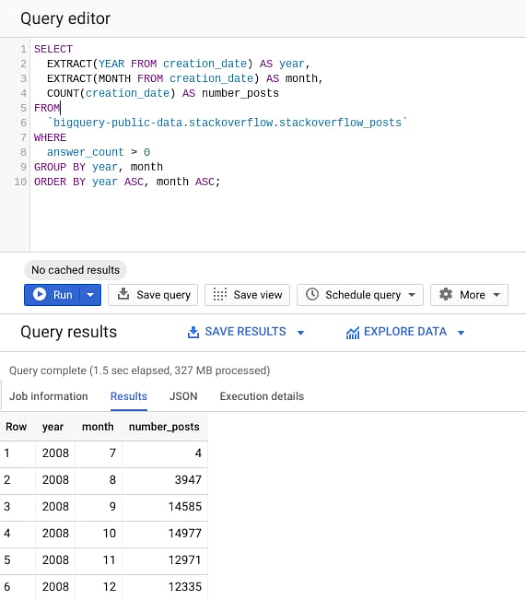
Rõ ràng từ kết quả truy vấn, chỉ mất chưa đầy 2 giây để phân tích 28GB dữ liệu và trả về kết quả. Công cụ BigQuery thông minh khi chỉ đọc các cột cần thiết để thực hiện truy vấn và chỉ xử lý 327 MB dữ liệu trong toàn bộ tập dữ liệu 28 GB.
Người dùng có thể mở rộng quy mô liên tục đến hàng chục petabyte vì các kỹ sư của BigQuery đã triển khai các tài nguyên cần thiết để đạt được quy mô này. Do đó, việc mở rộng quy mô chỉ đơn giản là vấn đề sử dụng BigQuery nhiều hơn, thay vì cung cấp các cụm lớn hơn. Tất nhiên, bạn cần ghi nhớ các phương pháp hay nhất và hạn ngạch sử dụng, và chúng ta sẽ thảo luận về những điều này sau trong loạt bài này.
Sử dụng BigQuery với tập dữ liệu lớn
Để có bản demo về những gì BigQuery có thể làm với một tập dữ liệu thực sự lớn, hãy xem bài nói chuyện này của Jordan Tigani khi phân tích ~ 1PB tập dữ liệu trong BigQuery trong vòng vài giây, với những cải tiến được thực hiện trong nhiều năm để cải thiện hiệu suất BigQuery.
Nguồn: https://cloud.google.com/blog/products/data-analytics/new-blog-series-bigquery-explained-overview




